How a Rare C++ Edge Case Took Down a Business-Critical Service
One evening, I was about to go home, but received an alert from a business-critical service. It looked horrible. About one-third of API queries were failing, and the number of failed requests per second was very high. I even laughed at the situation, because it was the fourth incident this year when I was on-call, just about to leave and received an alert. Does it look like planned problems?
My plans for a calm evening were ruined, one of the core services - crucial for business, was struggling with core-dumps and pods restarted one by one. I didn’t understand what was going on. Fortunately, only one-third of the queries failed, but thanks to retries it continued to handle customer requests.
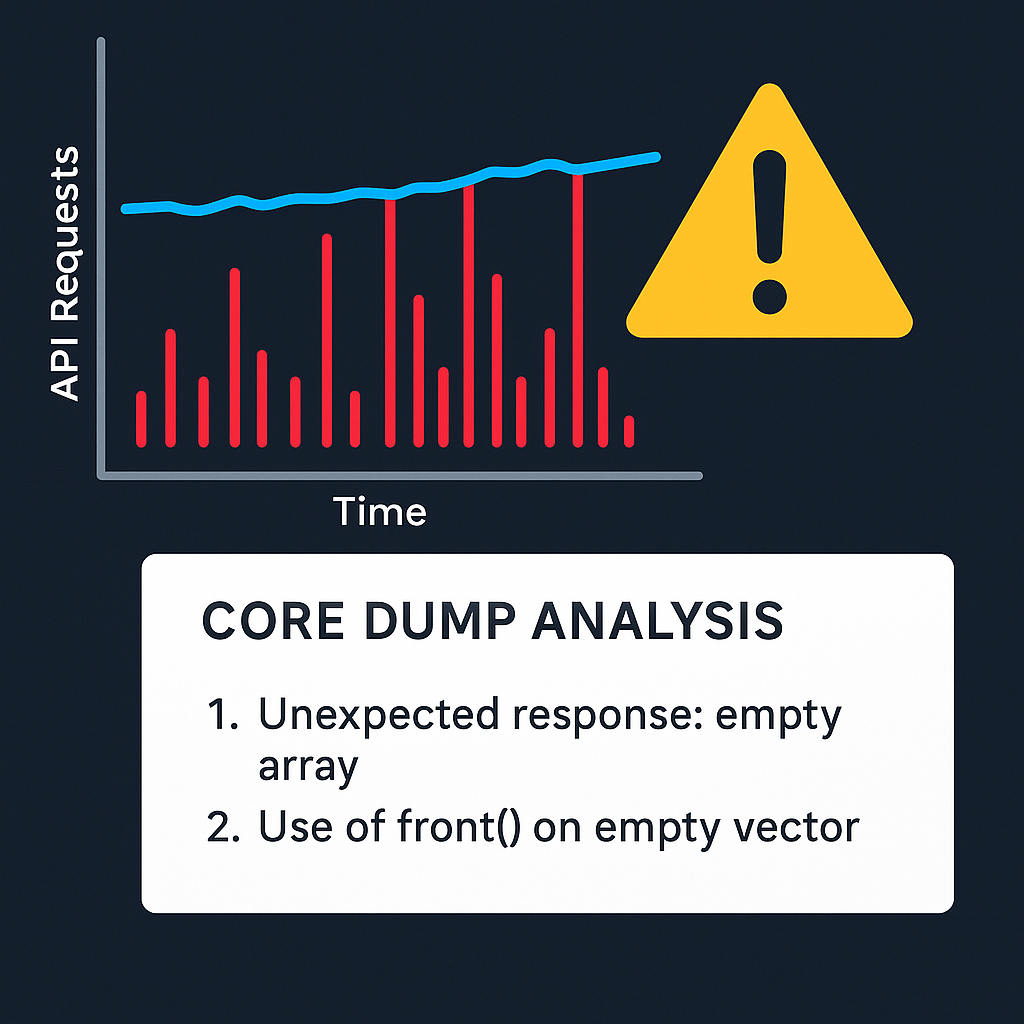
According to the on-call instructions I had to immediately find a way to stabilize the service, and then track down the root cause of the problem. For the first five minutes I didn’t understand what was going on. I tried to watch logs, but if the service crashes it couldn’t deliver the logs properly. The scale of the problem was gradually resolving, but I hadn't caught the problem yet. I noticed that the number of crashed pods decreased and the crashes occurred less and less often. It definitely looked like exponential backoff, so the problem was in some kind of queue handler, but I couldn’t determine which specific queue it was. I looked at monitoring dashboards and there were also interesting things: overall traffic rose by 30%, successful requests were still the same level, but 30% extra traffic was errors. So, I concluded that customers weren’t struggling, thanks to retries policies, but sometimes they could see annoying error messages.
Finally, I downloaded the core-dump and analyzed it. There were two problems in a few lines of code. First, the service received from external service an empty array. Our client model in code used `std::optional<std::vector<..>>` type as return value, where std::optional is null if some unexpected error occurred and service response hadn’t been received, but empty array was OK for model, but not for queue handler which checked only optional for emptiness, but not the value inside the std::vector. So, the second problem was the former engineer using the front() method instead of at(0) for getting the first element of the vector. In such cases calling front() at an empty array led to immediate program termination and produced a core-dump. In spite of the at(n) method that checks for out-of-range access and throws an exception if needed. Exceptions, in the worst case, lead to queue handler fall and one more attempt to handle this task later. This misuse of method led to service failure.
Talking about this situation I always remember the phrase of Neil Armstrong: “That's one small step for man, one giant leap for mankind”, but I would rephrase it due to my context: “That’s one small method usage for a software engineer, one big problem for the business”.
The next step, I quickly fixed a bug by adding a check to see if the vector was empty; asked my colleague to approve this merge-request and roll-out the release. As an action item for the next cross-team tech-sync meeting I’ll offer to add a linter rule and open a discussion about prohibiting usage of such unsafe methods, especially in cases where a safer alternative exists.
Have you ever have the same experience?
Member discussion